[ 2003-August-10 19:07 ]
This entry in the first Google Programming Contest is a tool that automatically builds site maps. Site maps are useful tools that can be found on most major web sites. However, accessing and navigating those site maps varies from site to site. SiteMapper attempts to automatically determine the hierarchical structure of a web site by analyzing its content. This site map can then be accessed as part of a web browser's user interface, or as a way of refining search results. Its results show that it is possible to automatically generate site maps with reasonable accuracy. More tweaking of the site mapping algorithm would improve it to the point that it would be a truly useful tool. Unfortunately, due to the size of the database the demonstration has been discontinued.
- Licence
- The Demonstration
- Potential Applications of Site Maps
- Generating Site Maps
- SiteMapper Database
- Scaling SiteMapper
- Building and Running the Demonstration
- References
Licence
The Google contest ripper add-on is released under the GPL, as it links against liburl which is GPLed. The remaining files are all released under the LGPL.
The Demonstration
The demonstration prototype builds a link database, analyses it to find pages that are on the same site and then uses this information to refine search results. The definition of a site is a collection of pages that is logically and structurally a single unit. These pages may be stored in a single directory as many personal pages are, or may span multiple domain names as some major sites do. The end user application is a Google search tool that accesses the Google database using the SOAP API and displays the first ten results. The results can then be expanded to show the structure of the site. Unfortunately, due to the size of the database the demonstration has been discontinued.
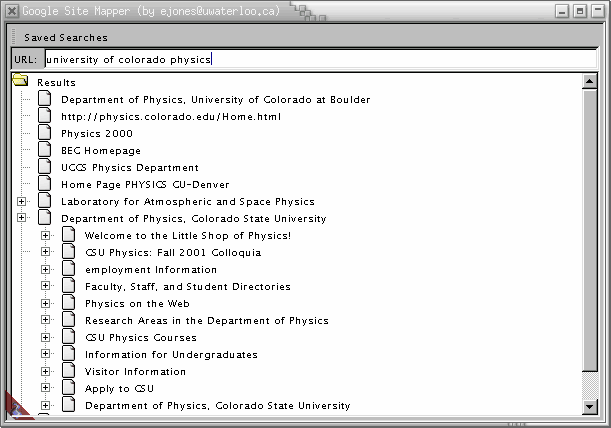
Try the saved searches from the pull down menu. Click the plus signs beside the results to see the site structure. Alternatively, type in some search terms and hit enter. If the URLs are found in the database, they will have pluses beside them. The database is composed of pages from American universities, so construct your search queries accordingly.
Potential Applications of Site Maps
Site maps are a common feature on many web sites. Since most sites are organized in a hierarchical structure, a hierarchical site map is a natural representation. They are useful tools for providing an overview of the structure and for locating specific information on a site. They are so ubiquitous that there is an entire book dedicated to them, Mapping Websites. According to a study of site map usability by Jakob Nielsen, "site maps [...] were fairly successful at getting users to destinations". However, he also concludes "current site maps are not good enough at communicating the site's information architecture", suggesting that there is significant room to improve site maps as navigational aids. Specifically, his study noted that "users hated non-standard user interfaces" and suggested that web browsers "pull the site map out of the website and make it a standardized [...] element".
That is not a new suggestion. One of the early releases of Mozilla attempted to implement it by loading a site map into its side bar, if the site provided one. This was a very interesting and potentially useful tool, however, very few sites provided RDF site maps that it required, and therefore it was useless. At some point along the development process, the feature was scrapped.
Dave Weiner wrote about a similar idea when discussing the possibilities of distributed web directories, similar to dmoz. He states "Google is the best at Search. It's weak at hierarchy (like everyone else)". As a solution, he proposes that people post hierarchies like site maps or directory categories on their web sites, in an XML format called OPML. When a search engine, such as Google, locates these hierarchies, it indexes them and ranks them just like it does to web sites. Users can perform keyword searches against a globally distributed and edited directory of the web, returning hierarchies of results. These same directories could also be used to improve the relevance of search results by being able to provide more relevant, human edited lists of related content. He also has been exploring hierarchical browsing using Google's related links feature, which is something that could be enhanced with site maps.
It is obvious that this is an idea that many are thinking about, so why aren't we all using site maps to navigate the web? The biggest stumbling block to these ideas is that it requires sites to provide an accurate, machine-readable site map. This is a big challenge. It is difficult enough to persuade content creators to use new web features like Cascading Style Sheets, it would be nearly impossible to get them to provide a site map that nearly no one is going to be able to see.
The solution is to have automatically generated site maps. That way, when a map is not provided by a web site, the user can still be presented with one. This would help the bootstrapping process by encouraging users to use the feature, and encouraging content creators to provide site maps to improve the user experience. SiteMapper is not the first attempt to automatically generate site maps. Many others have looked into this problem in the past, with varying degrees of success. However, what separates those attempts from this one are its scale. The previous work in this field has aimed at creating a tool to help web site creators build site maps. This tool attempts to do it to every web site in the world.
Generating Site Maps
Creating a site map automatically for a web site is a challenge. The web is, by its very nature, a decentralized and unorganized system. Structure exists in little pockets, but it is not easy to automatically locate it because each web site is structured differently. There is a set of common practices, such as organizing the URL structure of a site similarly to its content structure, but for each rule there are many exceptions.
Search engines face this same challenge. It is easy to match keywords against web pages, but it is hard to rank the results that are returned. Google has been so successful due to its PageRank technology, which uses links to determine the value of web pages. Since links are the key to the web, they are very accurate clues to its structure. SiteMapper uses links to locate sites for this very reason.
The concept that is used is very simple. SiteMapper considers two pages to be part of the same site if they link to each other. That means that page A has a link to page B, and page B has a link to page A. It is that simple. The reason that it works is that sites are, by their very definition, a collection of web pages that are linked together. It most cases, sites will have links from their top-level pages down to more specific pages. Each of these specific pages usually has links to all the top level pages, and many others as well. By gathering together the set of pages that are linked directly together, we get a good approximation of the contents of that site.
The second challenge, now that we have a set of pages that belong to the same site, is to organize that set of pages into a hierarchical structure. Again, the links are a good indicator of which pages are associated with others, however, it is not clear where to begin. The two algorithms that come to mind are to use the page that has the most links, as it is the most connected page, or to use the page that has the shortest URL, since in many cases that will be the top level of a site. SiteMapper uses the latter algorithm.
The Algorithm
- Iterate over the set of web pages, gathering the following information: URL, title, and which URLs it links to.
- Iterate over the set of links, copying any links that exist in both directions to a new database.
- Iterate over the new set of bi-directional links, copying the metadata for the URLs that are referenced.
- Iterate over this new set of URLs and generate the set of links belonging to each site:
- If the URL has a site assigned to it, continue to the next URL.
- Otherwise, collect all the URLs belonging to this site by recursively adding all the linked URLs to this site.
- Sort the set of URLs in the site. The root of the site is the first URL in the sorted list.
- Recurse for each URL, starting at the root URL, generating the hierarchical structure:
- Get the list of URLs that this URL links to.
- For each of those URLs, if they can be found in the sorted URL list, add them as children of this URL and then remove them from the list.
SiteMapper Database
The database that stores all the metadata to generate the site maps is very simple. It is based on the Sleepycat Berkeley DB, as it is fast, portable, simple and scalable. Berkeley DB is also a tried and tested product that has been used in many mission critical environments. One large drawback to Berkeley DB is that it only stores key/value pairs. As a result, a number of different database tables are needed. Another trade-off is that the DB only stores raw data. In the case of the site metadata, it was necessary to write a custom tree serialization routine so this richer information could be stored in the database.
- google-urls.db
- Stores the URL metadata (URL -> { URL, title })
- google-links-forward.db
- Stores the forward links (source URL -> destination URL)
- google-sites.db
- Stores the site metadata (site ID -> site hierarchy)
- google-url-to-site.db
- Stores the URL/site mapping (URL -> site ID)
Scaling SiteMapper
Writing SiteMapper as a Google Contest entry means that it was written as a part-time effort. As such, it was written to be correct first and fast second. It was optimized when building the databases was taking an unreasonable amount of time, however there is much room for optimization in the code. However, the database was designed to be distributed, and that design would make scaling SiteMapper from the Google Contest's 900 000 web pages to Google's 2 billion pages easier.
One performance optimization that is implement is to not use URLs as the actual keys in the DB. The reason for this is that URLs can be very long, and our database format would require us to have many copies of them in many locations. Instead, we represent URLs by a unique ID. However, to avoid a critical path that would bottleneck a distributed database, the unique ID is generated from the URL by using the MD5 hash algorithm. MD5 generates a cryptographically secure 128-bit number from the URL string. As MD5's output is randomly distributed, there is a nearly impossible chance of collision. In fact, no collision has been reported as ever being found. By using the MD5 hash, we have the advantage of shorter, unique IDs for URLs without requiring a central database to maintain the URL to ID map.
Another advantage of the MD5 has is that it is evenly distributed, which makes distributing the database duties to multiple machines easier. Simply assign a number of servers to the task, ideally a power of two, and assign each of them a segment of the MD5 number space. Those machines then will store the entire URL and link metadata for that space, and the URLs will be evenly distributed between the machines.
For more information about possibilities for speeding up SiteMapper, you can read my log that I wrote while working on it.
Building and Running SiteMapper
Requirements
- A Linux machine which can build the Google Contest ripper
- The pprepos.xx.bz2 Google Contest files
- zip
- A Java VM
- A reasonable amount of time, or a fast machine with tons of RAM
- A writable /tmp directory with 1.5 GB free space
Directions
Unfortunately, due to the size of the original source archive, building and running SiteMapper is now a lot more complicated. A number of software packages need to be downloaded separately and then built. If you will to fight with it a bit, it will be possible to get it to work, but it may not be easy. If you need assistance, email the author for assistance.
- Download the source archive
- Unpack it in the directory with the pprepos.xx.bz2 files. This should create the
google-sitemapsubdirectory. - Download Sleepycat Berkeley DB and unpack it into the google-sitemap directory. If you download a version different than 4.0.14 you will need to edit the Makefile.
- Download XML-RPC and unpack in into the google-sitemap directory. If you download a version different than 0.9.9, you will need to edit the Makefile.
- Change into the
google-sitemapdirectory. - Type
make. The Makefile should build the included required libraries (sleepycat db and XML-RPC for C/C++), install them into thegoogle-sitemapdirectory, then build the SiteMapper files. - Check that
google-sitemap/src/ripperandgoogle-sitemap/src/serverexists. If they do, it all worked. - Generate the site map database:
make database - Launch SiteMapper:
./launch.sh
Creating the Database
Converting the preparsed HTML files into a site map database is multiple pass process. The details are explained in the SiteMapper Database section. The first pass is to convert the preparsed files into a link database, using the Google ripper. The second pass extracts the interesting sites from this database into a second database. The third pass adds additional metadata to this second database to make it searchable. Luckily, the scripts in the Makefile should take care of all of this. Simply type make database in the google-sitemap directory. You should get two files: /tmp/google-urls.db and /tmp/google-forward-links.db.
Running the Demonstration
The demonstration application consists of two parts. The server is an XML-RPC interface to query for sitemap information. The client is an XWT application that talks to both the XML-RPC server and Google's SOAP API. To launch both parts of the application, type: ./launch.sh.
References
- Site Map Usability
- Mozilla Site Maps - Site maps used to be integrated into Mozilla
- Google, Directories, OPML - Building a distributed web hierarchy
- Google Outline Browser - Browses Google's "related links" as a hierarchy
- Exploring Google's Related Links - An exploration in browsing hierarchically
- Search Engine Makes Social Calls - Research into using links to identify communities
- Berkeley DB
- The MD5 Hash Algorithm