[ 2015-September-28 09:29 ]
In distributed systems, a standard technique to recover from errors is to resend a message if a response was not received after a timeout. Protocols such as 802.11, TCP, and many applications built on on HTTP requests rely on this mechanism. However: you absolutely must not naively retry all requests as soon as a timeout expires. This common mistake causes a feedback loop that makes every slightly overloaded service get swamped with a huge spike of requests. Instead, you must "back off" to avoid overloading the destination during a failure. At the moment, I think a good policy is to send a "backup request" after the 95th percentile latency, wait for both until an appropriate timeout, and never retry more than 10% of requests within a 5 minute interval. I'll explain why the naive policy is bad with my favorite technique: proof by example, using real-world failures from Twitter and AWS.
Let's first consider a very common, but naive retry policy. The client sends the request and waits up to 100 milliseconds. If the timeout expires, it cancels that request and sends another, waiting another 100 ms (e.g. Finagle's RetryingService with a TimeoutFilter). As traffic to the service increases, the response time also increases, eventually causing some requests time out. The client retries, and so the server receives more requests, making it even slower, causing more timeouts. This feedback loop ends with the server receiving twice the number of requests, causing it to be catastrophically overloaded.
As a real-world example, the graph below shows the requests per second arriving at a service at Twitter, during a situation where I got paged. The top line shows the total requests per second, while the others are the rates from each "upstream" service. Around 11:30, the traffic increases dramatically because another data center failed over for scheduled maintenance. Everything seems fine for nearly 30 minutes, although the traffic from Service B is actually slowly increasing. I believe this increase was caused by Service B timing out and retrying. At 12:00 this service has become slow enough to cause nearly all requests from Service B to time out, causing a massive spike in traffic. This caused most of the instances of this service to die (I no longer recall exactly why). The total traffic then drops, since there is nothing to receive and record it. Thankfully, Service B has a policy where after enough requests fail, it stops sending entirely, then slowly ramps back up. This allowed the instances to restart after the failure. However, the service was then in an "interesting" state, where the traffic from Service B would slowly ramp up, overload the service, then hammer it with a huge spike. This would cause lots of failures, so it would back off and repeat the process. Each spike caused a "downstream" service to get overloaded and restart. This situation persisted for two hours, until we figured out how to limit the load on the downstream service. This allowed it to survive the next spike by rejecting most of the requests, and the system stabilized.
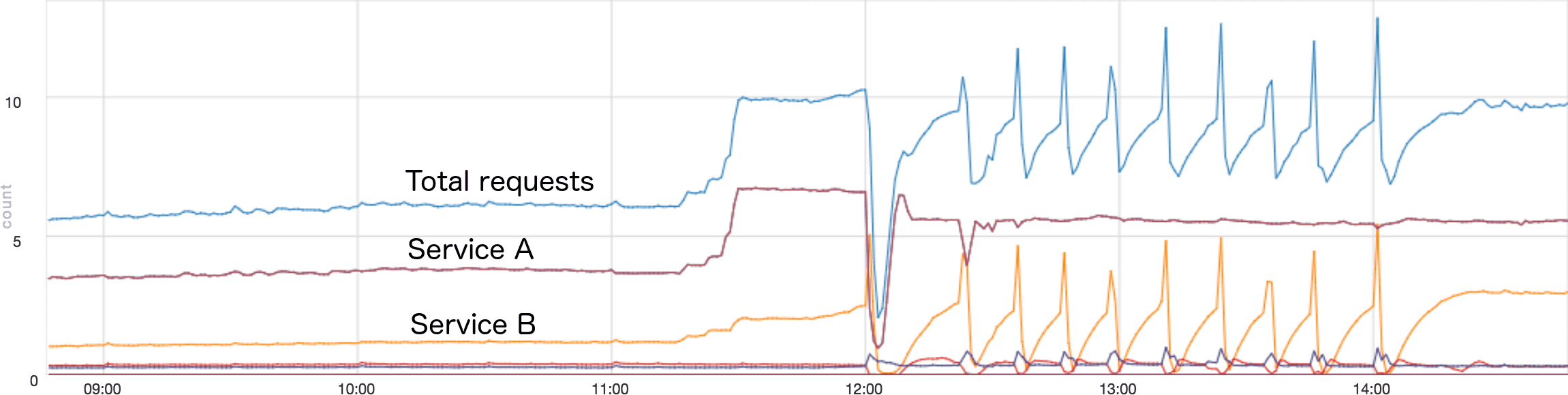
Service B's retry policy in this case was both good and bad. The good part is that after many requests fail, it stops sending then ramps back up slowly (a bit like TCP congestion control). This allowed the service to recover after each spike. The bad part is that each spike sent double the normal traffic, and killed our service.
[Update: 2015-09-28]: As a second real-world example, a few days before I wrote this, Amazon's DynamoDB key-value store service had a serious outage. In their postmortem, they describe how retries during this outage caused heavy load, so that "healthy storage servers [...] were having subsequent renewals fail and were transitioning back to an unavailable state." The load was so high that it was "preventing [Amazon] from successfully making the requisite administrative requests," when they tried to add more capacity. To prevent this failure in the future, Amazon is "reducing the rate at which storage nodes request membership data," which sounds to me like they are adjusting the retry policy.
Retries are very helpful when there is an temporary error or slowdown. In modern distributed systems, there are a wide variety of things that can cause these kinds of giltches, such as a network or CPU spike in a process on the same machine, an unusually long GC pause, or a hardware failure. The problem is when the entire system is slow because it is overloaded, retries make things worse. As a result: you must retry intelligently. The challenge is: what does "intelligent" mean?
Currently, I think a good default policy is to send a "backup request" after a percentile latency target (e.g. the 95th percentile), and wait for both up to a large, manually set timeout. In normal cases, this should cause approximately (1-percentile) (e.g. 5%) of extra requests. However, you must ensure that a client doesn't retry too much in catastrophic cases, where the server suddenly is much slower, so every request is taking longer than the percentile latency target. I think limiting the total percentage of retries in a time window seems reasonable (e.g. 2 × (1-percentile), or 10% within 5 minutes). This policy requires a single parameter: the overall request timeout before the client gives up, and it should prevent horrific overloads while lowering the long tail latency and masking temporary errors. I believe that in the Twitter scenario, if Service B had an upper limit on the maximum percentage of retries, our service would have handled the situation more gracefully by failing a fraction of requests for a short period of time, rather than failing most of them for two hours.
The piece that the solution I just described is missing is some "smart" rate limiting, to avoid overwhelming services in the first place, and to allow them to recover if something causes them to get dramatically slower. A standard solution is to manually set a limit on the number of concurrent requests being processed and queued, and have servers reject requests when they are overloaded. I think there is an opportunity for academic work on policies that do not require manual tuning, provide good throughput, but don't allow services to become catastrophically overloaded. It seems like it should be possible to apply the same approaches used for congestion control in networks to RPC systems. I've done a brief literature search, and there is remarkably little work in this area. If you know of something I should read, please email me.